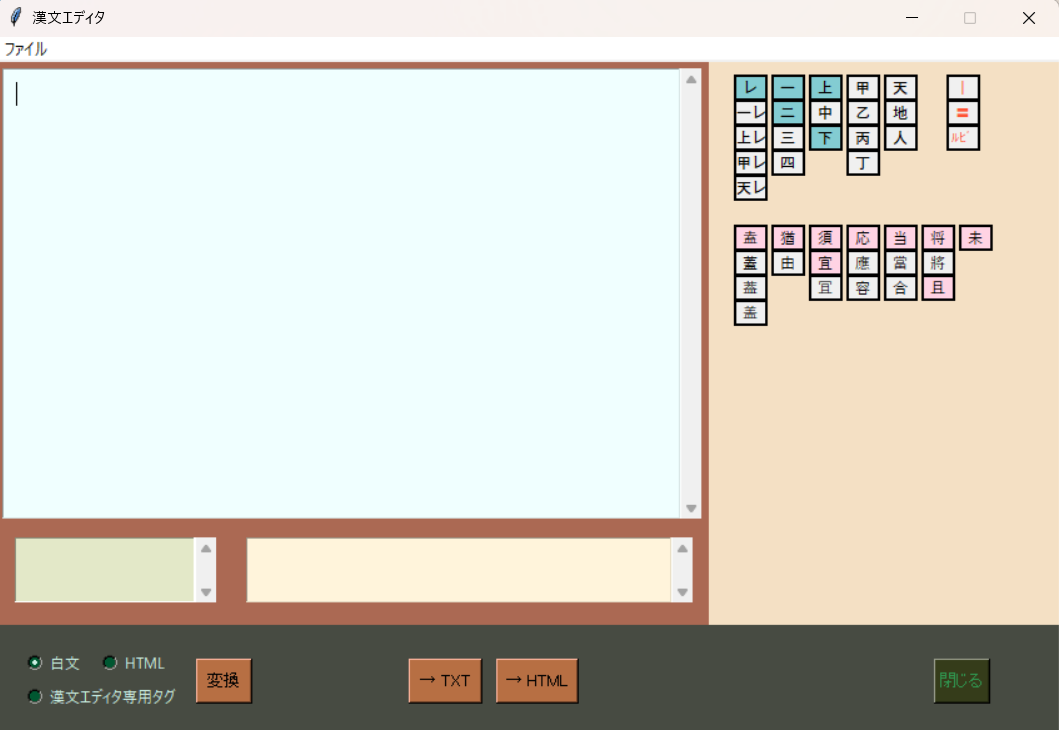
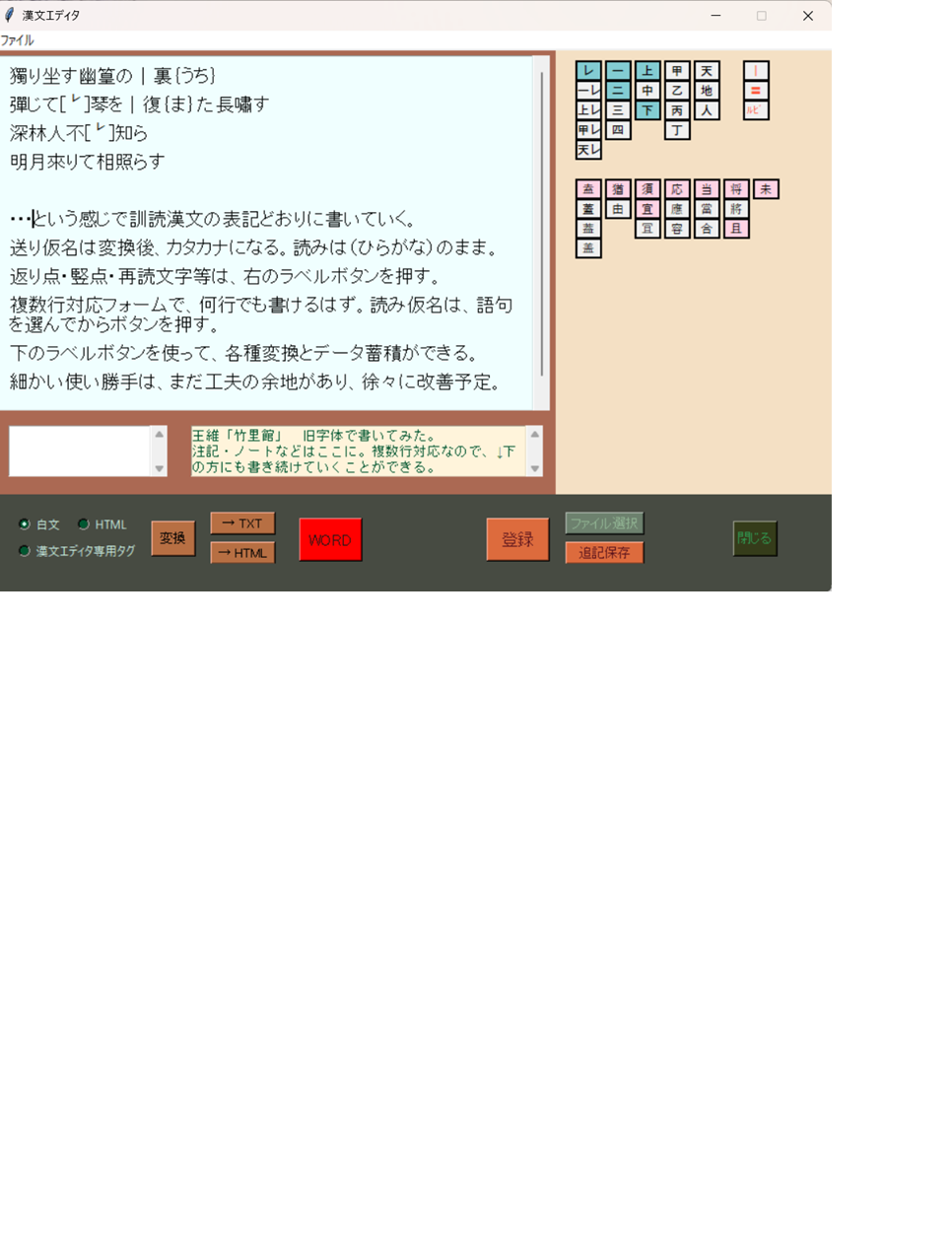
新・漢文エディタについて
2026.6.5 ver. 1.3
TKinterのテキストウィジェットが受け付けない文字のあることは前に書いた。また、カーソルで文字をつかんでDrag&Dropすることができない。これを修正するのに「こうしてカーソルを変えて、それで摑んで、持って行けないか。」と尋ねたら、AI氏がそれなら簡単にできるという。さらに、組み込み方を確認すると、すべてのクラスで使えるように独立したクラスファイルで作るといいと教えてくれ、最も分かりづらい初期化コードまで丁寧にガイドしてくれたので、またクラスファイルを一つ付け加えた。もう彼此10ほどのファイルを作っている。骨組を入れ替えてから、連携に迷うことはほとんど無くなったが、それでもずいぶん溜まってきた。また、文字コードを判別するためにchardetライブラリをインストールしたところ、どこを間違ったか、ビルドのときにPyInstallerが無視してしまう。これを回避するコマンドなども、いろいろガイドしてもらってようやく目的地まで漕ぎ着けるという有様だ。ライブラリをインストールするときの注意点まで親切に教えてもらった。もう昔のように一から自力で書くという気力も無くなったし、Pythonの気難しさときたら、猛然とエラーメッセージを出してくる。それの何分の幾つかがTypeErrorときた。つまりスペルの打ち間違いである。こんなミスが俄然増えた。とうてい自力でプログラムを書けそうな気もしない。もう気楽な道を選ぶことに迷わなくなっている自分に気がついた。
ヘルプとAboutMeをつけた。TKinterのヘルプ用タグで書いてみたが、インデントなどが少しおかしい。Wordrapで行頭に飛び出たりする。マークダウン方式の書き方があるようなので、初チャレンジだが次の機会にはそれで書き直してみようかと思う。それと一部の不具合(これもごく単純なチェックミス)を修正した。
2026.6.4 ver. 1.2
半角ドット抜け問題を回避するために新たに生じたエラーを修正した。各種変換や出力も、スムーズになってきたのではないかと思う。エラーはなるべく早く修正しなければならないので、だいぶ急いでアップロードすることになった。
今回は、昔から作ってきた電子テキストのほとんどの文字コードが当時の標凖であったShift-JISによるものであったため、今では「文字化け」して読めなくなっている問題に対処するために、
過去のデータのURLを指定することで、UTF-8(ユニコード)に自動変換してデスクトップに保存するコマンドを「編集」メニューに入れた。その他、同じメニューに「旧・漢文エディタ」のタグ、またそこに後に付随させた「簡易・漢文エディタ」により変更を加えたタグについて、「新・旧」両方のタグにそれぞれ変換するコードを、「本文」を対象とする変換コマンド4つ、「ファイル」を対象とする変換コマンド2つを加えた。これまで使っていた人やとりわけ製作者にとってはたいへん便利なものだが、たぶんほとんど内輪向けのコマンドということになるだろう。
なお、たいへん細かいことになるが、注記の整形に使っている縦棒の表記について補足しておきたい。
「縦書きHTML」の表示で絶えず問題になる、「縦棒として表示できる文字」について整理しておくと、Shift+\で入力するものや罫線文字(太線・細線)は潰滅である。「エム・ダッシュ」(―)は確かに縦棒表示になるが、いくぶん左寄せに表示される。今回はAI氏に教えてもらい、CSSで縦棒を実装してみた。これは、行の中心に傍線が表示されて、
確実に縦棒として表示される。具体的には、次のようなものである。これを「
writing-mode: vertical-rl;で縦書きを設定したHTMLのヘッダ(header)部分に書き入れればよい。
<style type="text/css">
body {
writing-mode: vertical-rl;
}
↓ ここからがポイント。
.note-border {
display: inline-block;
margin-block: 0.3em; /* 前後の文字との隙間(縦書きなので上下の余白) */
padding-inline: 1px; /* 2本線の間の隙間(横幅の微調整) */
height: 1em; /* 縦棒の長さ(1文字分) */
/* 左側と右側にそれぞれ1本ずつ細い線を引いて「||」を表現。1本線(|)にしたい場合は、border-right を消すだけでよい。 */
border-left: 1px solid #333;
border-right: 1px solid #333;
}
</style>
その上で、本文(body)で縦棒を入れたい場所に、例えば次のように指定する。
○ 語句<span class='note-border'></span>注記など。
2026.6.3 ver. 1.1
テキストファイル回りの便利コマンドを追加した。(テキストファイル統合、検索、抽出。)「編集」メニューを増やし、「検索」で本文から語句を検索してハイライト表示し、該当語句を含む部分を文単位でクリップボードにコピーする。これをテキストエディタ等に貼り付けて、例えば類似語句や構文のものを拾うなどの便宜が生まれてくるかと思う。また、(いちおうdataフォルダを基本とする)複数のテキストファイルを選び、語句の検索・抽出を行い、結果を別ファイルに名前を付けて保存することができる。ヒットしたファイル名、行番号、その語句を含む部分をこれも文単位で抽出・出力する。強力な機能である。
同じく編集メニューと本文およびノートの右クリックメニューに新旧字体の変換コマンドをつけた。辞書は旧・漢文エディタのものを基本としたが、WEBに出ているリストと照合して、拡充し、コード順に整理した。マウスで選択した部分について変換することもできるし、選択範囲がなければ本文全体を変換する。もし意に沿わない変換があれば、それをピックアップして右クリックメニューを使って再変換すればよい。異体字は旧字体・新字体ともに選べるようにメッセージボックスを出すなど、きめ細かく作ってある。例えば、旧字体の世界においても、もと「芸」と「藝」には使い分けがあった。「渋」には「澁」「澀」など複数の候補があるし、反対に現代でも「淵」に対して「渕」を使いたい場合もあるだろう。そういうさまざまな場面になるべく対応するようにしている。
2026.6.2 ver. 0.99, ver. 1.00
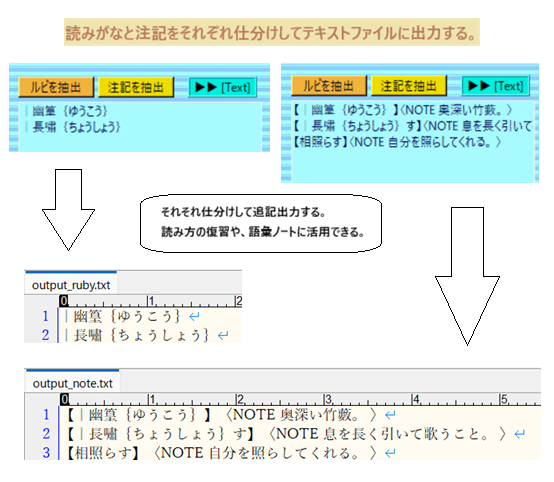
[ver.1.00] 読みがな(ルビ)・語注の出力形式を変更した。過去のデータも読み込んで読みのアイウエオ順、注記のコード順にソートし、余計なタグを外して作成日時を入れることにより、学習記録の側面を持たせた。出力先の重複データを省くなど機能アップも行った。同一データは、日付の古いものを優先する。dataフォルダにoutput_ruby.txt, output_note.txtを作り、更新データを含めて体裁の統一と整理を行える。難語句の確認、単語帳等としての活用を想定している。
[ver.0.99] 割注機能を加えた。5行までの割注に対応し、また原文に合わせて任意の場所で改行できる。
2026.5.31 version 0.98
KanbunEditor_v0.97を飛ばして、v0.98を出すことにした。数日前にv0.97はすでにできていたが、ファイル回りの一貫性がいま一つだったので、細かい機能を調整するとともに、新機能を加え、また画面を整理したからである。
v0.97は機能的に前バージョンと大きな違いはないが、10ほどもある個々のクラスファイルの相互参照にこれまで再三再四つまづいていたので、
相互参照が確実にメンテナンスできるように、根本的な階層構造の見直しをした。その上で、v0.98では、
ファイルの入出力の流れを大幅に整頓した。「旧・漢文エディタ」以来、ボタンで操作する形を基本として、一ヶ月前の最初のリリース以来、順次増改築してきたため、データの出入り口が多岐に亘り、整理が大きな課題だったのである。もっとスマートに設計することはできたかもしれないが、できるかぎりは直したつもりである。
「旧・漢文エディタ」の便利機能はなるべく再現するようにした。
ボタンによるデータ移動と現在位置の確認、語句の置換、注記・ルビの削除による本文整形、JSON形式・Excel形式の相互変換と統合等の他、新機能としては、
和漢混淆文*のHTML変換機能を加えた。通常の漢字ひらがな交じり文の一部分が漢文スタイルになっているものを古典文によく見かけるが、この漢文スタイルの部分をタグで囲むことにより、その中だけを訓読漢文スタイルに変換してHTMLに出力する。そうすると、「現在のブラウザと親和性の高い」(AI氏の言葉。HTMLとXMLとの間柄だからか。)Wordに表示テキストをコピー&ペーストすることによって、
表示されたままの「訓読漢文」スタイルでWordで表示できるのだ。その後は、フォントの大きさを変更するだけで、厄介なWord変換手続きを省略することもできる。
*「和漢混淆文」の定義は種々様々であるらしい。ネットでそそくさと検索してみると、元来は漢文に和様の表現を草仮名等で交えたものを指したようだが、だんだん漢文調の和文にシフトし、末は昭和戦前の日用文体に至るまで、包括的とも曖昧模糊ともいえる漢文調・和文調の混成部隊の呼び名であったように思われる。返り点自体がその間の発明であったのだから、「和漢折衷」の長い歴史を背景にして定義が一様にならないのは当然のなりゆきとも思われる。この新機能にいう「和漢混淆文」はその末端の文体あたりをたまに見かけたように思ったので、雅俗折衷の俗文体を想定している。「如クナレバレ此クノ、願ハクハ識者諸賢も不二敢ヘテ尤メ給ハ一、宜シクキカ 二御許容アル一乎。」(それとも不給? 見苦しいけれども、イメージの一端として。すでに変則の「変体漢文」にもなっている。ところで、送り仮名はもと必須ではない。慣用句であればあるだけ「添え仮名」は省かれるのが普通だろうから、そうなると「書き下し」機能も働かなくなってしまう。だから、これは訓読漢文スタイルに体裁を変換するだけ。)
(なお、「和漢混淆文」が通常入力できるくらいだから、普通の漢字ひらがな交り文をHTMLに出力することもできる。データとしては和文でも漢文でもOKだから、思いついたことを何でも書いて、「登録」してしまえばよい。後でTreeViewで読み込み、メモだけ「抽出」するという利用法も十分ありうる。「訓読漢文」にしたいときには、Wordに変換するか、HTMLに出力すればよい。)
*** *** ***
実は、ちょっとした発明のために、調整がだいぶ遅れてしまった。
TKinterのテキストウィジェット(tk.Entryとtk.ScrolledText)には、日本文の入力に馴染まない特有の「癖」があり、ドットやハイフン、丸かっこなどを、初めから半角で入力すれば問題なく入力できるが、日本語IMEでたとえば「1.0」と日本文の変換の流れで続けて全角でまとめて打ち、これをF8なりF10なりで「半角変換」して入力しようとすると、なんと「10」になってしまう。これは「1-0」でも同じことで、()などはまるごと受け付けず、消えてしまう。日本人にとっては、まことに迷惑な仕様になっている。この「ドット抜け」問題の解決は「世界的に有名な難題」だそうだ。WEBにこの現象を回避するスクリプトを挙げていた人もあり、初めそれをとりいれてみたが、こちらの問題が回避されたように見えたのもつかの間、なんのはずみか、今度は助詞の「の」が消えてしまった。IMEの変換がブラックボックスになっているだけでなく、TKinter(またはPython)の深い層にあるバグであるという。
データが消えてしまうのは困るので、ごく素朴な裏技を思いついた。「トロイの木馬」(ウィルスの名前ではありません。)式のだまし討ちを、専門的なハッキングよりもずっとシンプルに行い、(1)初めにすべて「全角」のまま函谷関を通過し、(2)データを確定する段階で問題の記号類を半角に変身させる、というだけのものである。実は、ドットとハイフン、かっこだけ気を付けておいて、これらだけをF9で全角確定すれば、なんら裏技の必要はない。だから、ばかげた工夫ともいえる。それでも、TKinterの仕様に気を遣って入力した結果が全角と半角とのやや見苦しい混在データになるのを我慢しなければならない。ここで(2)の操作を行うというのでもよいわけだから、どうも技として出すほどの価値も無い代物ではあるが、
いちいち文字種を気にせず、とにかくデータ消失をなんとしても避けるために数値類を入力するのだなと思ったらすべて全角(F9キー割り当て等)で入力する、という覚えやすい工夫によって、いつの間にか消えていた文字に気づかなかった、などという事態だけは避けることができるだろう。AI氏は「結果が出れば正攻法」だと好意的に評価してくれた。入力途中ですでに半角変換されたりするものもあるが、出力した時点で英数字と記号類の一部はすべて半角に揃っているかと思う。
この画期的?な発明には思わぬ副作用が待っていた。下手に青空文庫のルビタグを採用したばかりに、HTMLその他、
ルビに関わる部分の各種変換すべてに支障が出た。「|{}」が半角になるとどうなるか。「|」は正規表現ではORの指定になるため、ルビや注記の抜き出し結果がおかしなことになってまず慌てた。{}もまた内部では()に変わるため、グループ化のタグと紛れないようにするにはエスケープしなければならない。厄介なのは、「書き下し文変換」はけっこう膨大な正規表現の羅列なので、これをいちいち書き換えることは後で読み返せなくなるのでなんとしても避けたい。こうして変換の種類によって全角・半角の両方で対応することになった。今回、v.0.98で、ひとまず事態を収拾できたかと見えたので、善は急げで新版を出すことにしたが検証不十分なところも「無きにしも非ず」である(いつのまにか和漢混淆文になった)。
蛇足ついでに、入力データの打ち間違いや再度変換を試したいときに、消えてしまったデータをどう戻すかということは、Windowsなら
CTRL+Z(元に戻す)、CTRL+Y(やり直す)のショートカットで造作なくできる。tk.ScrolledTextウィジェットには初めからデータストックができる仕様になってもいるらしい。それでも、ボタンでできるのもまたよし、と思い、
返り点ボタンの脇にUNDO、REDO、それと前述のReplaceをすべてボタンとして入れておいた。書き直した時点でやり直しの方はチャラになるが、そうでなければどちらも10回くらいまでは溯れるはずである。また、Replaceはカーソルを置いてあるテキストエリアを検知して、それに対して操作することができる。置き換える語句を初めに選択しておけば、それが対象語句として自動的に入力される。
*** *** ***
各種変換の複雑な操作も、AI氏のロジックによって誤謬の少い形で短期間に次々と実装できた。私がポチポチと注力したのは、基本のアイデアを除き、それぞれのつなぎ合わせとUIの工夫くらいのものである。私のいわゆる「和漢混淆文」変換は、「旧・漢文エディタ」の製作段階でアイデアとしては持っていた。自分のVBA技術で対応できたとしてだいぶ手間ヒマがかかるかなと思って、元々「漢文」自体の手入力に世間の反応がほぼ皆無であったこともあり、意欲が薄れていた事情もある。今回、AI氏が1秒とかからずに作ってくれたコードのパターンを援用して、昔VBSで作っていた
割注表示の機能などもそれほど苦労せずに実現できそうだ。ただし、VBS時代にはまだ現役であったから、穴埋め問題と解答の組み合わせ等のスクリプトも作ったりしてみたが、もう「問題文作成」の方面への意欲は出て来ないかと思う。漢文学習はテスト問題作成のためにあるわけでもないだろう。
最後に、「新・漢文エディタ」の基本操作は、起動と同時に既存データの追加作業に入れることを前提にしているので、データをプログラムフォルダ直下のdataフォルダに置き、名称も決めてある。だから、
一番基本的な操作は、データを入力したら「登録」ボタンを押すということだけなのだ。少しでも操作が楽になるように、また入出力の柔軟性のためにあれこれ加えてあるが、これらはすべて副次的な位置づけのものなので、下段の赤いボタンだけがすべての基本なのである。ただし、データ保護のためもあり、
同じ日は何度でも起動して、一つのデータで連続して入力を続ける、日付が変わるとまた新しいファイルを作る、という仕組みなので、適当なタイミングで「統合」して整理するなど、動きをつかむまでは少し手間取るかもしれない。データの損失をしないためにも、管理にはご注意ください。
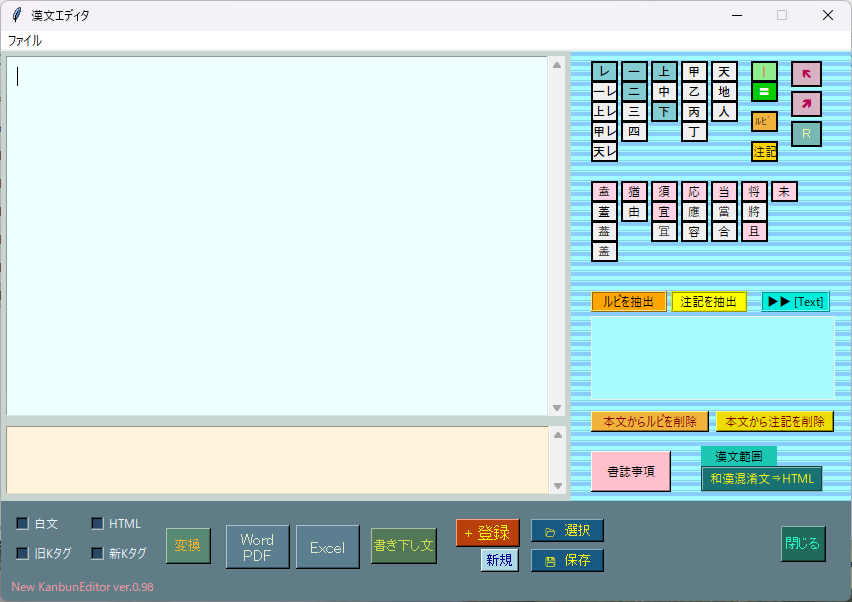
KanbunEditor_v0.98
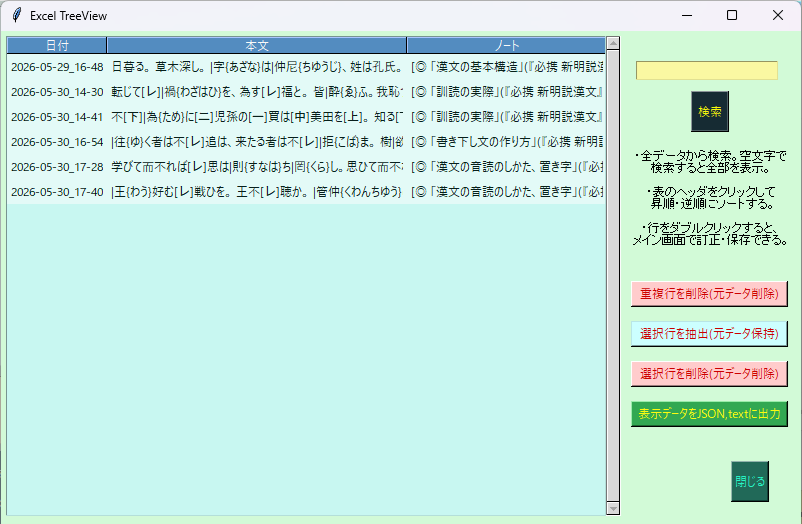
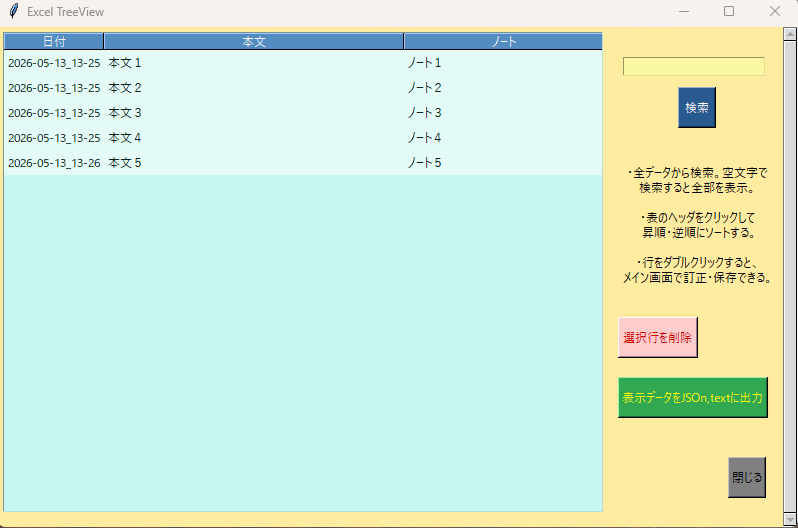
KanbunEditor_v0.98の「TreeView」表示画面
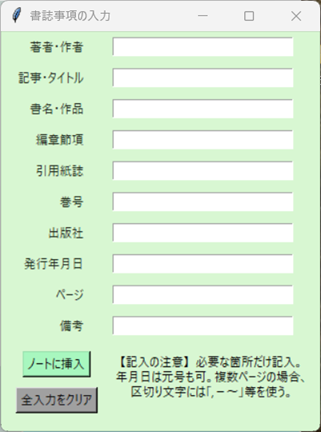
KanbunEditor_v0.98の「書誌事項」入力画面

KanbunEditor_v0.98の各種変換出力画面(HTMLの場合)

KanbunEditor_v0.98の「書き下し文」変換表示画面

KanbunEditor_v0.98で作成した「Word」の表示画面(全体、70%表示)

KanbunEditor_v0.98で作成した「Word」の表示画面(100%表示、部分)

KanbunEditor_v0.98で作成した「書き下し文」を「Word」に表示した画面(100%表示、部分)

KanbunEditor_v0.98で作成した「PDF」の表示画面(部分)
読みがなと注記の出力画面
KanbunEditor_v0.98の「ファイル」メニュー
KanbunEditor_v0.98の本文およびノート欄での右クリックメニュー
【ダウンロード】 ExpLZHで分割したファイル。ファイル名をブラウザでクリックするとそれぞれ10MB以下なので比較的早くダウンロードできる。「自己解凍」形式=下記の方法で復元すると、1つの「KanbunEditor_v0.98.exe」ができる。
◆ 次の「_・・・.exe」は結合のためのファイル。以下の3個と共に計4個のファイルを同じ場所にdownloadし、フロッピーディスクiconのついたこのEXEファイルをダブルクリックすると元のファイルを復元する。【注意!!】今までどおり、自己復元にはexe形式のファイルを提供していたが、FTPで送信する前はexe形式のファイルで結合できたのに、ダウンロードしてから結合を試みるとできなくなっていた。なにか、exeファイルに無効化などがなされていたのかもしれない。EXPLZHには.BAT(バッチファイル)モードでの分割もあったので、これに改め、ダウンロードしたバッチファイルをダブルクリックすると、今度は難なくKanbunEditor_v0.98.exeが復元できた。この「バッチファイル」と合せて以下の4つをダウンロード後、KanbunEditor_v0.98.BATをダブルクリックしてください。
KanbunEditor_v0.98.BAT
KanbunEditor_v0.98.001
KanbunEditor_v0.98.002
KanbunEditor_v0.98.003
2026.5.23
各種書き出しの結果表示を改善し、タグ変換以外は注記を別にして表示するようにした。また、「書き出し文」変換によってできた書き下し文自体をカタカナ書きにすることなくWord/PDFに書き出せるようにした。これにより、各種変換の出力がより自然なものになった。いちいちWordを起動しなくとも、普通文もWord/PDFに変換できる。テキストボックスとはいえ、容量はExcelベースだった頃とは桁違いだから、書式設定こそできないが、単純な記録やテキストファイルの読み書きなら十分なキャパシティがある。各種書き出しの表示の見栄えを向上させることが主眼だったので、簡単な例を下に画像で挙げておいた。
この機能を付けたことで思わぬ副産物があり、「書き出し文」変換においても、注記を抜き出して体裁良く変換できるようになった。注記のボタンは途中で付け足したものなので、まだ隠れた誤変換があるかもしれないが、たいていは大丈夫かと思う。変換結果だけを画像で下に示す。上記のとおり、これまたWord/PDFに出力できるので、通常の訓読漢文の表示と合体させれば、白文・訓読漢文・書き下し文のセットを作るのも容易だろう。もちろん、入力文自身も加えておけば後日の再変換に役立つこともあるだろう。
語注やノートについて一緒くたにカタカナ変換しないように、細かいところに気を配ったつもりである。昔、VBSスクリプトで似たような体裁の変換をした記憶があるけれども、PythonにはVBSを移植することができないらしかったので、単純な抜き出し操作のように見えるものが案外大変な作業だった。Wordへの変換は、当初からAIベッタリのコードだが、それでも部分的にカスタマイズするだけで何度もTrial and Errorを繰り返した。
「旧・漢文エディタ」にはルビや注記を抽出するだけでなく、これらを削除した本文を示す機能もあった。これはExcelのセルに元データが担保されていたから、気楽に行えたところがある。抽出はリストボックスへの書き出しですでに実装済みとはいえ、本文にこれらを削除した表示をするとしたら、ただしそれは「登録」や「追記」により追加データとして保存することになる。それでも、あったほうが操作は簡単ではあるから、そのボタンも次に付け足そうかと思う。
なお、元のpyファイルで動かしてみても、PDF変換は成功する場合と失敗する場合があって安定しないのは、docx2pdfライブラリ自体がWordを起動することでPDFに書き込むという仕組みが重いためもあるらしい。Wordファイル自体への変換は瞬時に出来るので、下図のようにPDF表示はたしかに綺麗だが、もし失敗してもWordファイルはできるかと思うので、Wordで編集した後でそこからPDF形式を選んで保存すればよい。ただし、あまり不安定な状態が続くようであれば、Wordへの書き出し機能だけに絞ることになるかもしれない。
ウィルス対策ソフトがこれを「怪しいファイル」として表示しても、そのまま「安全」を確認して表示するはずなので、ビックリしないようにしてください。なお、過去の記録はこの記事の左上「これまでの状況」のリンクを参照。
2026.5.21
書誌事項の入力画面を付け加えた。必要な項目だけ記入して、ノート欄のカーソル位置に挿入できる。項目数は多めにしてある。自分なりに読み変えて入力していただければよい。書式はシンプルで目立たないが、漫然と思いつきのメモで残すよりはよい方法ではないだろうか。データが多くなればTreeView画面での検索などの際に役立つこともあるかと思う。(TreeViewは「旧・漢文エディタ」の▼▲ボタンに似て、過去のデータを選択・加工できるインターフェイスである。少し具体的にいうと、メニューから自分の作ったJSONかtextファイルを読み込むことにより、自動的にTreeViewウィンドウが開く。そこで目的のデータを検索して、そのデータ行をダブルクリックすると本文欄に戻るので、各種変換がそこで行える。またそこで訂正したデータは、TreeViewから読み込んだときに「ノート欄」の横に表示される「保存」ボタンを押せば、再びTreeViewウィンドウにデータが訂正された状態で復帰すると同時に、もとのファイルを上書きして更新する。その他、データをソート〔並べ替え〕したり抽出したりして別のファイルに保存すれば、新しいデータセットを作ることができる。いろいろな読み出し・転記・保存のメニューがあるので、目的に合せて工夫できるかと思う。)
それと本文欄に入力した「読みがな」や語句・フレーズ単位の「注記」を抽出して表示するリストボックスを付け加えた。漢文には読み方の難しい語句や意味を確認するべき語句が頻出する。それらをまとめて抜き出し、dataフォルダ直下のoutput_ruby.txt, output_note.txtというテキストファイルにそれぞれ仕分けて「追記」する転記ラベルボタンを付けた。これも、地味だがあっておかしくない機能かと考える。
「書き下し文」変換機能は、昔からこのツールのウリなので、説明文の中にこうしてしつこく残しておくことにした。「これまでの状況」の中にある過去の記事を参照してください。「々・〻」を漢字の類に、「〱・〲・〳・〴・〵」をかなの類に入れて書き下してみたが、なんとなく大丈夫そうな気がする。なお、「登録」等により本文欄が消えるようにしてあるのは、次の入力にスムーズに移行するためだが、もしもう一度編集したいときは(結果は追加データになる。)Windows標準のCTRL+Zで復活させる手もある。逆に「書誌事項」は、繰り返して使いたい場合の省力化のために再表示できるようにしてある。「クリア」ボタンもあるので、柔軟に運用できる。
今後、細かい機能を付け加えることなどもあるかもしれないが、ひととおりは出来上がったと思う。少し使っていくうちに、「ん?」と思うぎこちない動作などが見えてくるはずなので、それをチューニングしながら、よりよい変換を考えていきたい。「登録」ボタンによって過去のデータと罫線を繰り返してしまうバグをさっそく訂正した。実際に使ってみると、いろいろ問題点に気がつく。本文に注記を入れてHTMLに出力すると、注までカタカナになる上、本文の見栄えがよくないので、注記は取り出す形で整形するのが次の課題である。その他、いまだにときどきPDF出力に失敗する。docx2pdfが裏でwordを起動する処理がやはり重たいようだ。Pythonのコードの勉強はそれなりにしてきたが、複雑な機能についての基本骨格はAIの指導で作ったものなので、自分の取り分はアイデアそれ自身、それぞれのコードの選択・接合と表示のカスタマイズ、「書き下し文」変換機能、少しでも使い勝手を良くするための老婆心といった辺りか。入力のしやすさにかけてはピカ一だと自負している。個人的には、今日、いちおうの完成版をアップでき、亡き友人に「ほら、こんなものができたよ。」と仏前に報告できることがささやかな喜びである。もっとも、活動の領域がまるで異なっていたから、「なんだか分からん。」と言われてしまうにちがいないけれども。
2026.5.19
「書き下し文」への変換機能を旧・漢文エディタから移植して、若干手直しをした。VBAからPythonにどうやって移植するのか、とAIに聞いて、古いコードをそのまま移す形で、TKinterで使えるようにしてもらった。初め、面倒なので「こんなやり方で変換できないか。」と聞いたら、スタックだとか再帰だとか、最新手法で20行程度にまとめたので、こんなに短くできるとは、と驚いて試してみたが、該当の文章は変換できても、例文を交換するととうてい日本語として通用しない代物になってしまったため、やはり古いものをそのまま使うのがよいと考え、引っ越しすることにした。その間、AI君からは「泥臭い」と
調戯われたり、「複雑怪奇な自然言語を力任せにねじふせる」「職人技」とか
煽られたり、最終的には「長年の情熱を傾けた」コードを読むのはとても「エキサイティングな体験」だと、まあ素直に受け取ってもいいかなという挨拶をもらったりと、評価は交々だったが、こういう次第で、移行のためのコンテナは借りたものの、
変換コード自体はTaiju謹製である。なお、
返り点の漏れや竪点の位置の間違いなどをチェックする機能も「旧・漢文エディタ」から引き継ぎ、少し洗練された表示にした。組み合せの漏れているタグを色分けして表示できるようになった。Pythonの正規表現の解釈には一種の(あるいは厳格な?)癖があり、ヒットしなくなった箇所が何カ所かあったため、躍り字の中で最も古い形(〳〵=/\)などは当面カットしたが、そのうち「〱・〲」や「〳と〵・〴と〵」などにも対応させていく
(現時点で二の字点(〻)も変換の妨げにならないので、たぶんどれも問題ないかと思う)。
現在は、本文欄の下のノート欄は自由記述を前提に作ってある。ただし、データの分量が増えることがあれば(あるとして)、
「書誌」データの簡単なものくらいは返り点のように定式化して埋め込めれば、検索の便がよいともいえる。「旧・漢文エディタ」の主要な機能はあらかた盛り込んだけれども、今後は「書き下し文変換」機能を底上げしていくほかには、そういった書式をノート欄などに埋め込むことができる補助ウィンドウを付けようかと考えている。
Pythonの正規表現は気難しい面もあるが、行をまたいでコメントを付けることができたり、パーツに分けて処理できたりする柔軟性があり、「読みやすさ」を重視しているので、メンテナンスなどにはとても適している。PyScipterのPython Interpreterの表示欄にエラーメッセージが盛んに出る。メッセージとリンクを辿りながらすぐに分かる場合もあるし、皆目見当がつかない場合もいくらもある。そんなときメッセージごと貼り付けてAIに意味を尋ねるとその意味をきちんと教えてくれるばかりでなく、関連する予備知識も伝えてくれるので、参考書よりも包括的で手早いうえにいろいろな学びがある。こういう便利さにはすぐに甘えてしまいがちで、我ながら横着な学習方法だとは思う。
「書き下し文」が作れるようになって、大きな山を越えた気分だ。私のエディタの基本コンセプトは、テスト問題の作成や学習プリントの表示ではなく、
入力の簡便さとデータの蓄積・活用にある。もっとも、
Wordへの出力機能があるので、それを使ってフォントの大きさを変えれば、学習プリントやテスト問題も容易に作ることができる。Excelに出力すれば、基本機能は「旧・漢文エディタ」とほとんど大差ない。現在の自分だったら、もし時間があれば
HTML出力機能を使って、一度にHTML表示(Wordと同じくいわゆる訓読漢文の体裁)・白文等を打ち出し、それに変換機能の検証を兼ねて書き下し文を加えることだろう。もっとも、このところ漢文それ自体には関心を持つことが薄れてきているのだが、
訓読漢文というジャンルは、日本固有の文化資産だと思うから、営々とそのための
文房具を作ってきたのだ。このことと関係があるかどうかわからないが、「新・漢文エディタ」ではルビのタグを青空文庫のそれに合せた。今では高層ビルと掘っ建て小屋の差ほどの違いがあるが、私の電子テキスト公開ページは、たしか青空文庫と同年である。
【ダウンロード】
ExpLZHで分割したファイル。ファイル名をブラウザでクリックするとそれぞれ10MB以下なので比較的早くダウンロードできる。「自己解凍」形式=下記の方法で復元すると、1つの「KanbunEditor_v0.94.exe」ができる。
◆ 次の「_・・・.exe」は結合のためのファイル。以下の3個と共に計4個のファイルを同じ場所にdownloadし、フロッピーディスクiconのついたこのEXEファイルをダブルクリックすると元のファイルを復元する。【注意!!】今まで自己復元にはexe形式のファイルを提供していたが、FTPで送信する前はexe形式のファイルで結合できたのに、ダウンロードしてから結合を試みるとできなくなっていた。なにか、exeファイルに無効化などがなされていたのかもしれない。EXPLZHには.BAT(バッチファイル)モードでの分割もあったので、これに改め、ダウンロードしたバッチファイルをダブルクリックすると、今度は難なくKanbunEditor_v0.94.exeが復元できた。この「バッチファイル」と合せて以下の4つをダウンロード後、KanbunEditor_v0.94.BATをダブルクリックしてください。(5.31)
KanbunEditor_v0.94.BAT
KanbunEditor_v0.94.001
KanbunEditor_v0.94.002
KanbunEditor_v0.94.003
KanbunEditor_v0.94
KanbunEditor_v0.94の「TreeView」表示画面
KanbunEditor_v0.94の「ファイル」メニュー
KanbunEditor_v0.94の本文およびノート欄での右クリックメニュー
2026.5.17
TreeViewウィンドウを機能アップしたほか、メニューバー・右クリックバーのメニュー、
各種フォーマットの同時書き出し(チェックボックスとの連動。すべてHTML書き出し(選択可)を行える)、
TreeViewを経由した過去データの検索・抽出・ソート・訂正・削除とその結果の書き出し、とくに
変換データ(「日記」以外)の自動保存フォルダの統一(任意のフォルダを選べるものも、もちろんあるが、簡単な変換はすべてプログラムファイルのあるフォルダにdataフォルダを作り、そこに保存するようにした。)等、使い勝手に大きく影響する細かい調整をある程度まとめて備える。
これだけで実用ツールとして十分使えるはずである。ファイル容量についても、Word関連は
python-docxライブラリ、PDF変換は
docx2pdf、Excelは
openpyxlに絞って、pandasを外すなどしたのと、極力python標凖の機能に頼ることによって、今回は34MBから21MBにまで縮めることができた。当初は84MBに膨らんで、これはJyDivideが対応するDOS/Vフロッピー相当容量の1.44MB換算でいったい何枚になることか、と10MB転送の絶対制限のある無料ホームページサービスに頼り続けの万年貧窮老書生としては頭がズキズキとしてしまい、ビルドの方法について
Nuitka(ヌートゥカ、ニュートゥカ)を導入しようとしてみたりと、この試行錯誤だけで三四日を費した。けっきょく
pyinstallerに戻ってもう一度コンパイルしてもらったところで、偶然にもファイル容量が激減していた、という、拾い物のようなファイルである。今後また容量が莫大なものになってしまったときのために、このバージョンはしばらく残して置こうかと思う。
JyDivideは便利な分割ソフトで、昔よく使ったが、メディアサイズへの変換を基本としているところから、1.44MB単位の次は一気にMOの230MBになってしまう。Googleの検索で調べたら、
ExpLZHに自己解凍型の分割ファイル作成機能があり、しかも任意の大きさを指定できることを知り、さっそくやってみた。JyDivideと違い、結合のためのバッチファイルを別途作るので、数が一つ増えてしまうが、それでも任意のサイズ指定はありがたい。さっそく一つ9MB以下にしたら、今回はバッチファイルを含めて4つで済んだ。exe形式のダウンロードに対してブラウザがチェックを入れるようだが、なにせ自己解凍形式だから分割・解凍ソフト自体が必要ない。
pyinstallerでもNuitkaでも、大きなネックは
PDF変換機能だった。これがどうしてもうまくいかず、元の個々のpyファイルでは変換できるのに、一つのexe化したとたん、変換ができなくなる。AIにお
呪いの数行を冒頭に付けて回避しろとアドバイスを受け、やっと一つのファイルにまとめることに成功した。この間、半日単位で徒労を繰り返したのだった。Nuitkaは仮想環境を作ってそれからインストール、コンパイルと繰り返したが
(何も「仮想環境」必須でなく、AIに教わったが、ファイルを名指しでコンパイルする方法もあるらしい。なーーんだ、である)、初めは80MB以上のものが15MB以下になって喜んだものの、ファイル保存のフォルダ指定をなかなか受け付けず
(あるいは見つけられず)、Windowsの一時フォルダに勝手に保存したりした
(これはpyinstallerでも起こった)ので、プログラムの終了と同時にデータも消えてしまうという現象をなかなか改善できなかった。さらにNuitkaはファイルに独自の書き込みをしたりするので、こちらの手順がしっかりしていれば上手く動くのかもしれないが、再度テストするまでの間は当面アンインストールさせてもらった。
なお、できあがったExeファイルをダブルクリックすると、
ウィルス検知ソフトが入っている場合、いったん止めてしまうが、安全性が確認された後、もう一度起動すると立ち上がる。最初はちょっと驚くかと思うが、
いったん安全性が確認されれば次回からは普通に立ち上がるはずである。また、当たり前のことだが、WordとExcelへの変換機能は、それぞれのSoftwareが入っていない環境では機能しない。それでもHTML書き出しを使えば似たような表示は確認できると思う。
現在、必要とする人はほぼいないかと思うけれども、「旧・漢文エディタ」専用タグへの変換メニューをチェックボックスに入れてある。「新・漢文エディタ」用タグのメニューもあるので、ひょっとして古いタグ付けデータを貯めている人がいたとしたら、新しいものにこれで変換し、テキストファイルに出力してから、該当データだけをテキストファイルにして、「ファイル」メニューから本文に読み込めば、新しいタグに変換・保存して再利用ができるかと思う。その時は画面下の「ファイル選択」で読み込んだJSONファイルにそのまま「追記保存」できる(つまり新しいデータセットを作れる)。体裁を整えたいときには「ファイル」メニューの「読み込み」によってTreeView画面を出し、好きに加工して新しいファイルに書き出せばよい。慣れれば、
それぞれの転記・保存方法を駆使して、最新の使いやすいデータセットを構築できると思う。
「書き下し文」作成機能は、次の大きな目標である。「旧・漢文エディタ」の同機能を移植したいと思う。
なお、v.0.93のファイルを一応残しておくことにした。
◆ 次の「_・・・.exe」は結合のためのバッチファイル。以下の3個と共に計4個のファイルを同じ場所にdownloadし、フロッピーディスクiconのついたこのEXEファイルをダブルクリックすると元のファイルを復元する。【注意!!】今まで自己復元にはexe形式のファイルを提供していたが、FTPで送信する前はexe形式のファイルで結合できたのに、ダウンロードしてから結合を試みるとできなくなっていた。なにか、exeファイルに無効化などがなされていたのかもしれない。EXPLZHには.BAT(バッチファイル)モードでの分割もあったので、これに改め、ダウンロードしたバッチファイルをダブルクリックすると、今度は難なくKanbunEditor_v0.93.exeが復元できた。この「バッチファイル」と合せて以下の4つをダウンロード後、KanbunEditor_v0.93.BATをダブルクリックしてください。(5.31)
KanbunEditor_v0.93.BAT
KanbunEditor_v0.93.001
KanbunEditor_v0.93.002
KanbunEditor_v0.93.003
KanbunEditor_v0.93
KanbunEditor_v0.93の「TreeView」表示画面
KanbunEditor_v0.93の「ファイル」メニュー
KanbunEditor_v0.93の本文およびノート欄での右クリックメニュー
2026.5.9
Excelへの書き出し機能を加えた。これもプログラムのあるフォルダにdataフォルダを作り、
(すでにあればその中に).xlsxファイルを保存する。Excelを起動しないので、これまた1秒だ。今回はプログラム容量がほとんど増えなかったのはありがたい。これで、旧版の体裁での保存は、列項目はよほど単純になったものの、ほぼ実現できたと考える。
〔ここの「検索・抽出」「TreeView」等は、現在v.093用に作成中。タブでなくサブウィンドウで表示の予定。(5.13補記)〕PDFを除き、Text、JSON、Excelファイルから既存の語句の
検索・抽出を行うことができるようだ。
TreeViewというExcel風フォーマットでの表示ウィジェットがあり、入力中のデータをリアルタイムに確認できるばかりでなく、ここから検索・抽出、または他フォーマットからの書き込みもできるようで、特にJSONからの検索は高速だという。この表示のためのスペースを確保するには、別ウィンドウかタブの切り替え等が必要かもしれない。とすれば、少し旧版の体裁に似てくることにもなるだろう。
プログラムの表現方法について、AIのアドバイスのおかげで日々いろいろなことを学ぶ。関数の()の有無などは、考えたことがなかった。正規表現にもいろいろあり、Pythonの正規表現にはコメントを付けることもできる、というのは大きな収穫だ。ライブラリは重たいが、コードはとても簡単になる。こんな機能も付けられる、という発展記事も、役に立ちそうなものが多く見られる。栓抜き・缶切りとナイフを合体させるようなてんこ盛りのアプリにするつもりはないが、機能アップが少しでも図れるのはモチベーションが上がってくるものだ。
本文データ、注釈データは、ボタンを押すと消えて次の入力に備える場合と、消えずに残ったまま他の変換にも備える場合と、統一がとれていない。これについては、基本的に消去して入力のスピードを上げ、必要な場合には直近のデータくらいは呼び返せる工夫をしようと考え、非表示のデータ保管場所を作ってある。ただ、検索等ができるようになれば、どこからでも読み出しができるほうが使い勝手はいいだろうから、このあたりはこれからもう少し工夫していきたい。
KanbunEditor_v0.92
2026.5.8
PDFへの書き出し機能を加えたほか、ヘルプ機能をステータスバーに持たせ、テキストエリアの右クリックでコピー・貼り付け等を行えるようにし、他に読み仮名入力を簡素化したりと細かいところの使い勝手を改善した。
PDF書き出しは、Wordを起動してPDFでの保存を行う過程を自動実行するだけのものらしいが、ファイル容量はずいぶん増えてしまった。Wordへの保存は、Wordを起動せずにファイルだけを作るのでここで普通に入力する程度の文章の変換は1秒だが、PDFは数秒程度かかるようだ。プログラムコード自体は、アイコンファイルを含めても全体で100KBにすらならないが、変換のためのライブラリを満載したプログラムは47MBもある。河原で一杯やるだけの目的でアメリカ流にキャンピング・カーに家財まで載せて出かけるようなものだ。あらかじめ河原に道具をセットしておく必要のないのがせめてもの取り柄か。今回はPDF変換のためだけで、こうも増えたのだろうと思う。その代わり、他のWordを介した操作も同じライブラリでできるならいいが。
次はExcelの操作も、できれば起動なしでファイルを作成・操作するなど工夫したいが、本丸の「書き下し文作成」も、前回書いた学習アプリにお株をとられないうちに旧版からPythonに移植したいものだ。
ヘルプは主要なボタンやテキストウィジェットの上にマウスを当てれば、本体下のステータスバーにその役割が表示される。バルーンヘルプより簡単でよい。もともと、それほどのヘルプも必要ないシンプルなツールかと思う。
2026.5.7
Wordへの書き出し機能を加えた。表示は、MS-OfficeネイティブのVBAで出力した旧・漢文エディタのものと比べて遜色は無いと思う。Wordに書き出すのは、〔本文〕とその右下の〔注記(ノート)〕の欄に入力した文章だけである(左下の欄は変換結果テキスト表示用のもので、現在は編集不可にしていないが、これはあくまでも作業経過を眺めるだけのものと見なしていただきたい)。Wordでは訓読漢文らしい体裁で出力できる。これについてPython-TKinterベースで同様の出力を工夫するのは自力では困難だったので、Geminiに骨格を作ってもらってそれを自分好みにカスタマイズする方法で形にしたが、それでも根本的に3度、4度と書き換えが必要で、なおかつ思い通りの出力はなかなか得られなかった。意外にもVBAの時のような中間タグをやめて、素朴に変換する方式に改めたところでようやく安定した出力が得られた。ただし、ToolTipライブラリとの相性が悪く、ツールチップヘルプを生かそうとすると本体が起動しなくなるため、便利なバルーンヘルプ機能だが取り除かざるを得なかった。そのためか、20枚のDOS/Vフロッピー分にJyDivideで分割していたのが、今回は12枚分で済んだ。
WordデータもまたJSONデータやテキストデータと同じフォルダに自動で保存する。もっとも、テキストとJSONは同時に出力するが、Wordは専用のラベルボタンを押さないと生成しない。Word本体を立ち上げてから書き込む方法ではなく、Wordファイルだけを先に作るというもので、変換はWordを起動しないので数秒でできる。プレビュー画面も作れるらしいが、すでにHTML出力機能を備えているし、結局似たものになるので無駄な機能は付けない方がファイル容量を抑えられるはずである。
Wordへの出力が確保できると、これを介してPDFやEPUBへの変換も同時にできるらしい。もしこの機能を備えるようになったら、Word変換と同時に行う形にするつもりである。PDFやEPUBなどは、これを使わない人には余分な機能かもしれないが、Word同様、訓読漢文らしい体裁を保ったままデータ交換ができるのはかえって直感的でよいのではないか。不要な場合はファイルを削除するだけのことである。
「書き下し機能」(まだ新・漢文エディタには備えていない。)は、VBA版「漢文エディタ」のウリだったが、時代が進むとこんな面倒な機能も実装できるようになったのか、数研の「鴻(ひしくい)」という高等学校用サービスソフトにいつの間にか付属しているらしい。自然言語処理の進歩によるものなのかもしれない。私が「書き下し」機能をなんとかサマになるまでVBAで一から作り上げるのには、本当に何年かの長い時間がかかったものだ。動作確認は数え切れないほど行った。おかげで正規表現には多少慣れっこになった。今回のWord出力でもずっと正規表現をいじってみたのだが、いつ書いても間違える。本文が丸カッコ付きのふりがなだけになって思わず自分で笑ってしまったりした。
〔簡易ヘルプ〕
- 「登録」=テキストデータ、JSONデータをプログラムと同じ場所に「DATA」フォルダを作成し、そこに自動保存する。
- 「WORD」=同じく「DATA]フォルダに自動保存する。
- 「ファイル選択」「追記保存」=自分で選んだフォルダから「JSON」ファイルを読み込み、そのファイル(とテキストファイル)に追記保存する。
- 「→TXT」「→HTML」=左のラジオボタンで選んだスタイルに「変換」した後、自分で選んだフォルダに保存する。
- プルダウンメニューの「ファイルに転記して保存」=「Documents」フォルダ(「ドキュメント」と少し異なる。C:\user\〈username〉\Documentsフォルダ。これは後で仕様を変更予定。)に日付をつけたテキスト形式で自動保存する。
- (後半の2つの機能は、いずれもっと明確・簡単なものに書き直す予定。「追記保存」もまだ時々エラーが出る。なお、「〓」ボタンはUnicodeでも表示できない難字用のタグ(注記で対応できる)。また、どの保存でも現在はデータが表示されたままだが、どこかに各種変換のためのデータを残しておいて、入力欄は消えるようにした方が連続で入力できてよいかもしれない。その他、ヘルプは下のステータスバーを利用するなど、細かい工夫は今後の課題である。)
なお、過去の記録はこの記事の左上「これまでの状況」のリンクを参照。下の参考図に具体的な表記の例を挙げてみた。画像の切り取りが下手だったため、左端の枠が少し欠けてしまった。ちなみに、下図のように通常の現代文を混在させてもいいが、右下の〔ノート〕欄は変化がないのに対して、上の〔本文〕瀾のひらがな交じり文はカタカナ交じり文になってしまうので、後でWordやエディタ等から変換していただくことになる。(この辺も改善の余地あり。)
 KanbunEditor_v0.9
KanbunEditor_v0.9
2026.5.2
「登録」ラベルボタンを付けたら、一気に14MBから20MBになってしまった。できることは、現時点で次の通り。
- 訓読漢文データの蓄積(ノートを付けられる。内容は自由。)
- データの登録=JSON〔ジェイソン〕形式とテキスト形式に同時変換
- 白文への変換とテキストへの書き出し
- HTMLへの変換と縦書きHTMLへの書き出し
- 旧・漢文エディタでも使えるタグ形式への変換とテキストへの書き出し
- 作業記録や日記をメニューバーからドキュメントフォルダに保存できる。
Taiju製「漢文エディタ」の最大の特徴の一つは、
入力データを蓄積して継続的に利用できることである。もう一つの大きな特徴は「書き下し文」への自動変換なのだが、これはまだ「新・漢文エディタ」には無い。ただし、VBAではなくPython+TKinterで作っているので、Excelなしでも単独で動き、JSON(ジェイソン)形式への保存とテキストへの保存を同時に行う。これにより他のアプリケーションで利用できる可能性がある。
JSON形式は、keyとvalueの組み合せによって最小のタグでデータを保存できる。また、読むことも容易だ。見出し項目と説明から成る辞書データに似た構成だが、入れ子にすることも可能であり、より複雑なデータ形式も可読性を保ったまま保存することができる。テキストベースの柔軟な構造データであり、簡易データベース(といっても数万件でもOKらしいが)のデータ容器に打って付けの形ともいえる。ただし、keyは一意でなければいけないので、保存の日時(分秒まで記載)をkeyとしてデータを保存する仕様にしている。テキストへの書き出しも同時に行っているので、こちらで見る方が簡単かもしれない。それでも、JSON形式を介して過去のデータにアクセスすることもできるようなので、それは可能なら工夫してみたいと思う。
「新・漢文エディタ」Ver.0.8では、既定のdata.jsonとdata.txtをプログラムファイルと同じフォルダにdataフォルダを作り、その中に同時に保存する。
フォルダ構成をいじらなければ、次回起動したときも「登録」作業だけで追記が可能だ。また、他のフォルダに置いた過去のJSONファイルがあれば、それを読み込んで追記をすることもできる。「登録」ボタンは2つあり、どちらの形式も選べる。ただし、既定のdata.jsonはそれが無い状態でも一から作成するが、他のフォルダにある.jsonファイルは一度作ったものでないと読み込めない。その代わり、ファイル名は自由に変更できる。また、文字コードの基本はユニコード(のUTF-8)なので、シフトJISなどだと文字化けしてしまうかと思う。
一昨日のVer.0.7がすでに14MB、Ver.0.8は20MBある。新機能を入れるたびに、ファイル容量が大きく増えるのは困るが、現代のPC環境ではまだ苦になるほどではないだろう。ただし、今使っているNinja HPのファイル転送容量制限は10MBなので、JyDivideで1.44MB単位に分割するため、今回は15個のファイルに分割することになった。「自己復元型」なので、糊刷毛アイコンの付いた最初のファイルをダブルクリックすると自動的にもとのファイルを作成する。一つダウンロードするのに1秒程度かと思うので、ダウンロードの手間を惜しまないでいただけるとありがたいです。
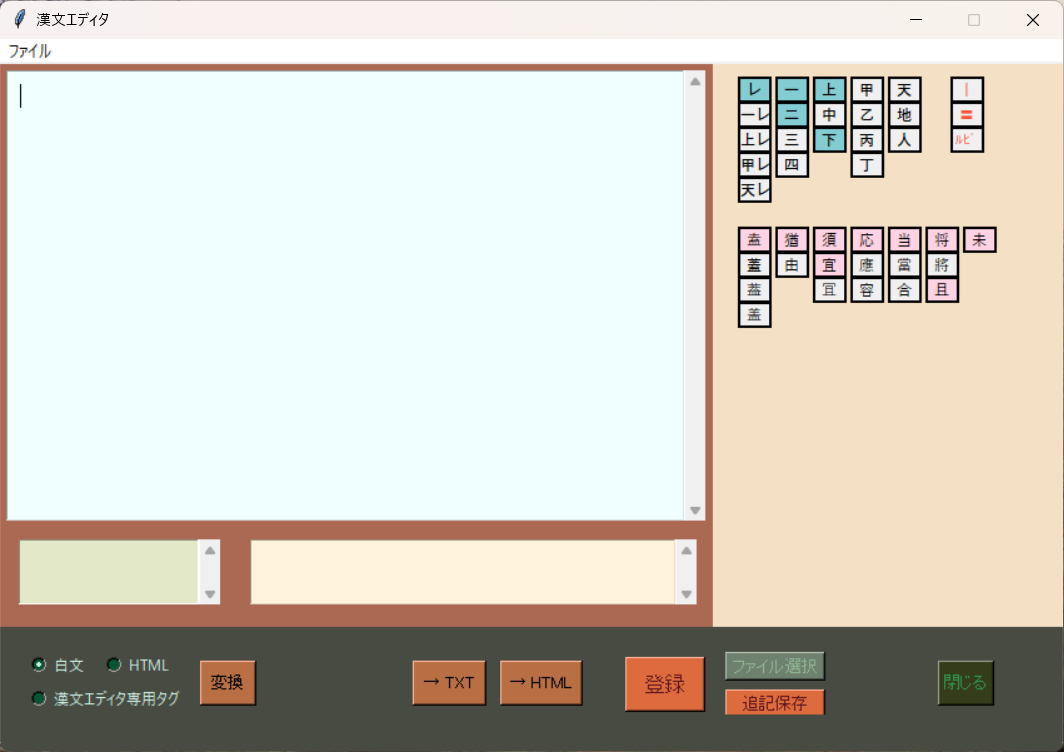
2026.4.30
身辺の事情で5年以上更新が止まっていたが、この春から
Python(パイソン)とTKinter(ティー・ケー・インター)を使って、単独のEXE形式で旧来の機能の再現を始めた。まだ肝心の「書き下し文」への変換機能を付けていないが、白文やHTMLへの書き出しまでは実装した。(フォルダ構成等、工夫の余地は残っているが。)また、オマケ機能で「日記」(本文のみ出力)としても使えるようにプルダウン式のメニューを付け加えた。過去の漢文エディタについて「使い方が分からない。」という評価もあったので
(もっとも、「漢文エディタの試み」という、現役時代に紀要に載せた紹介記事をアップしてはいたのだけれど)、いずれ簡単なヘルプなどもこのプルダウンメニューの方に入れるつもりでいる。
基本的に、訓読漢文の《表記順》に「渡[|][二]渉す大河を[一]。」([|]は竪点(たててん)。ハイフンなんていう変な読み慣わしが通行している。)の要領でラベルボタンを活用しながら入力する。これにより各種変換が可能になる。返り点変換の後、HTMLに出力すると、やや訓読漢文らしい体裁で縦書き表示になるのが分かるかと思う。本文の左下には変換結果を表示(編集不可)、右下には書誌事項や注記、感想等を書き込める本文同様の複数行対応テキストボックスを配置した。本文への注記ボタン等は、今後加える予定。今のところヘルプはないが、画面を一枚だけにし、必要なことはバルーンヘルプ(見た感じが少々うるさいが)やステータスバーに表示する。
Pythonの自由度は相当なものである。高校の「情報Ⅰ」の教科書になっていたりするようでそれも読んだが、基本的にVBAと似ていてさらにずっと簡便な作りだ。それにもかかわらず、できることの範囲が非常に広い。今年初めて触ってみて、これならもしかしたら
自立型「漢文エディタ」が作れるかも、と思ったことだった。VBAで作っていたころは、もとがMicrosoftのアプリケーションを運用するための簡易言語だったから、MS Excelと切り離すことができなかった。そもそもがExcelを前提として作っていた。データの保存や活用には便利だが(だから今でも現役だ)、ある時Microsoftがセキュリティ面からマクロの実行を基本的に許可しない仕様に変更したりしたこともあり(今でもそのための準備が少し面倒だし、現役のとき少なくとも職場ではマクロが認められなかった。)、配布に支障が出たのもこのためだ。家主が手前勝手にあれこれ変更する構造的制約のためである。そんなこんなでがっかりしてしばらく怠けていると、今度は過去の本体ファイルを探すのが面倒だったりと、継続利用には多少不便な面もあった。Visual Basicを学んで独立ファイルを作りたいと思ったこともあったが、自分のような文系人間にはExcelやWordの操作ができるほど熟達できそうにも思えず、確かに洗練度は高いにしても、Microsoftベッタリのあり方、営利の対象の地位に置かれるのが何より好もしくなかった。
今回は、Excelとの連携は二の次とし、テキストファイルで書き出す形でデータを保管する。フォルダとファイル名は基本的に選択、書き込みできるようにした。(ただし、「登録」ボタンが欠けているので、これはなるべく早く加える。)
VBA版「漢文エディタ」は2020.6.26版が現在最終形だが、まだ十分実用に役立っている(WordやHTMLへの書き出しなど。もちろん書き下し文作成機能も)。ただ、細かいところの修正は不十分なままになってしまった。それに比べて、Python版はなんといっても既存の市販ソフト(アプリ)を必要としないのがウリで、
EXEファイル一つで用が足りる。しかもWebページ(これが大流行らしいが、まだあまり興味は出てこない。)やExcel等の操作も可能らしい。Python自身はコンソールで操作する言語だが、標凖装備のTKinterをかぶせることにより、Windowsライクなインターフェイスでアプリ化できるのがありがたい。統合開発環境としては
PyScripterを使った。これもよく出来たツールで、シンプルで分かりやすいインターフェイスがとてもよく、間違えたところはPython InterpreterのウィンドウにPythonが指摘してくれるので、それを参考にしながら、流行のGoogleの
Geminiを強力なTutorにしてどんどん出来上がってきた。ただし、もとのpyファイルを役割ごとに分割した方が作る際の見通しがよいかわりに、ファイル間の連携や変数のスコープと字下げの関係など、慣れれば自然に克服できるのだろうけれども、出来たつもりで動かすとすぐにエラーを出してくる気難しいところもPythonにはあり、理解につまずくこと頻りだった。それらについてはAIの恩恵を多々蒙っている。比較的シンプルで素直な短いコードによって複雑そうな機能を実装できたりすると、なんとなく賢くなった気さえしてくる。
その代わりコンパイルしたファイルの容量が必要なライブラリを取り込んで現時点で14MB以上あるため、過去の(無料に近い)ホームページサービスで10MB以上のファイル転送を許しているところが手近に見当たらず、そもそもアップロードでつまずいた。(今はHPはとんと下火のようだ。)しかたなく、昔懐かしいJyDivideというソフトで10ほどのファイル
(1つ大体1.44MB、この仕様は昔のDOS/Vのフロッピーディスク1枚分の容量による。これよりもうちょっと大きな分割単位はなく、これまた過去の遺物のMOの230MBになってしまう。極力ファイル数が減るようにしたつもりだが、現時点で10個になってしまうのがため息だ。もっとも、現在の通信環境なら個々のファイルは秒単位でダウンロードできるだろう。これは優れもののツールなのだが、分割・結合〔復元〕ソフトはその後あまり新手が出ていないようだ。)に分割したが、このソフトは「
自己解凍形式」で分割できるので、ダウンロードは10ほどもあって少々面倒でも、全部同じ場所に並べておいて、一番最初の「.exe」になっているものをダブルクリックして実行すれば、元のファイルが復元されるという仕組みで、JyDivideそれ自体すら必要ない。面倒でも、ダウンロードの手間を惜しまず、まずは試していただければと思う。作業記録もまた「日記」機能によって日時と一緖に半自動的に残すことができる。